lunes, 27 de marzo de 2017
lunes, 23 de enero de 2012
Bases de datos orientadas a Objetos
Conceptos de orientación a objetos
Una clase tambi´en es un tipo de datos. De hecho una clase es una implementaci´on de lo que se conoce como un tipo abstracto de datos. El que una clase sea tambi´en un tipo de datos significa que una clase se puede utilizar como tipo de datos de un atributo.
El modelo est´andar ODMG
Un grupo de representantes de la industria de las bases de datos formaron el ODMG (Object Database Management Group) con el prop´osito de definir est´andares para los SGBD orientados a objetos. Este grupo propuso un modelo est´andar para la sem´antica de los objetos de una base de datos. Su ´ultima versi´on, ODMG 3.0, apareci´o en enero de 2000. Los principales componentes de la arquitectura ODMG para un SGBD orientado a objetos son los siguientes:
Modelo de objetos.
Lenguaje de definici´on de objetos (ODL).
Lenguaje de consulta de objetos (OQL).
Conexi´on con los lenguajes C++, Smalltalk y Java
El desarrollo del paradigma orientado a objetos aporta un gran cambio en el modo en que vemos los datos y los procedimientos que actúan sobre ellos. Tradicionalemente, los datos y los procedimientos se han almacenado separadamente: los datos y sus relaciones en la base de datos y los procedimientos en los programas de aplicación. La orientaci´on a objetos, sin embargo, combina los procedimientos de una entidad con sus datos.
Esta combinación se considera como un paso adelante en la gesti´on de datos. Las entidades son unidades autocontenidas que se pueden reutilizar con relativa facilidad. En lugar de ligar el comportamiento de una entidad a un programa de aplicaci´on, el comportamiento es parte de la entidad en sı, por lo en cualquier lugar en el que se utilice la entidad, se comporta de un modo predecible y conocido.
El modelo orientado a objetos también soporta relaciones de muchos a muchos, siendo el primer modelo que lo permite. Aun así se debe ser muy cuidadoso cuando se diseñan estas relaciones para evitar perdidas de información.
Por otra parte, las bases de datos orientadas a objetos son navegacionales: el acceso a los datos es a través de las relaciones, que se almacenan con los mismos datos. Esto se considera un paso atrás. Las bases de datos orientadas a objetos no son apropiadas para realizar consultas ad hoc, al contrario que las bases de datos relacionales, aunque normalmente las soportan. La naturaleza navegacional de las bases de datos orientadas a objetos implica que las consultas deben seguir relaciones predefinidas y que no pueden insertarse nuevas relaciones “al vuelo”.
No parece que las bases de datos orientadas a objetos vayan a reemplazar a las bases de datos relacionales en todas las aplicaciones del mismo modo en que ´estas reemplazaron a sus predecesoras. Los objetos han entrado en el mundo de las bases de datos de formas:
SGBD orientados a objetos puros: son SGBD basados completamente en el modelo orientado a objetos.
SGBD h´ıbridos u objeto–relacionales: son SGBD relacionales que permiten almacenar 3 objetos en sus relaciones (tablas).
A continuaci´on se definen los conceptos del paradigma orientado a objetos en programaci´on, ya que el modelo de datos orientado a objetos es una extensi´on del mismo.
Objeto. Es un elemento autocontenido utilizado por el programa. Los valores que almacena un objeto se denominan atributos, variables o propiedades. Los objetos pueden
realizar acciones, que se denominan m´etodos, servicios, funciones, procedimientos u operaciones. Los objetos tienen un gran sentido de la privacidad, por lo que s´olo dan informaci´on sobre s´ı mismos a trav´es de los m´etodos que poseen para compartir su infomaci´on. Tambi´en ocultan la implementaci´on de sus procedimientos, aunque es muy sencillo pedirles que los ejecuten. Los usuarios y los programas de aplicaci´on no pueden ver qu´e hay dentro de los m´etodos, s´olo pueden ver los resultados de ejecutarlos. A esto es a lo que se denomina ocultaci´on de informaci´on o encapsulamiento de datos. Cada objeto presenta una interface p´ublica al resto de objetos que pueden utilizarlo. Una de las mayores ventajas del encapsulamiento es que mientras que la interface p´ublica sea la misma, se puede cambiar la implementaci´on de los m´etodos sin que sea necesario informar al resto de objetos que los utilizan. Para pedir datos a un objeto o que ´este realice una acci´on se le debe enviar un mensaje. Un programa orientado a objetos es un conjunto de objetos que tienen atributos y m´etodos. Los objetos interact´uan envi´andose mensajes. La clave, por supuesto, es averiguar qu´e objetos necesita el programa y cu´ales deben ser sus atributos y sus m´etodos.
Clase. Es un patr´on o plantilla en la que se basan objetos que son similares. Cuando un programa crea un objeto de una clase, proporciona datos para sus variables y el objeto puede entonces utilizar los m´etodos que se han escrito para la clase. Todos los objetos creados a partir de la misma clase comparten los mismos procedimientos para sus m´etodos, tambi´en tienen los mismos tipos para sus datos, pero los valores pueden diferir.
El modelo est´andar ODMG
Un grupo de representantes de la industria de las bases de datos formaron el ODMG (Object Database Management Group) con el prop´osito de definir est´andares para los SGBD orientados a objetos. Este grupo propuso un modelo est´andar para la sem´antica de los objetos de una base de datos. Su ´ultima versi´on, ODMG 3.0, apareci´o en enero de 2000. Los principales componentes de la arquitectura ODMG para un SGBD orientado a objetos son los siguientes:
Modelo de objetos.
Lenguaje de definici´on de objetos (ODL).
Lenguaje de consulta de objetos (OQL).
Conexi´on con los lenguajes C++, Smalltalk y Java
viernes, 20 de enero de 2012
Conceptos avanzados de Modelo de Datos
La diferencie entre ambos modelos recae en que el modelo EER adiciona funcionalidades al ER, tales como el uso de cardinalidad, agregación, generalización. Asimismo, como los conceptos de superclases, retículas, entre otros. Todos estos serán explicados más adelante.
SUBCLASE: Grupo de elementos con algo en común, que pertenecen a una ENTIDAD.
Ejemplo:
Pertenecientes a EMPLEADO, tenemos las subclases INGENIERO, SECRETARIO, SUPERVISOR...
SUPERCLASE: Entidad de la que procede una SUBCLASE
ESPECIALIZACIÓN: Proceso para definir un conjunto de subclases de un tipo de Entidad (llamada SUPERCLASE).
– Pueden definirse varias subclases según distintos criterios.
Ejemplo: Empleado Ä Tipo de Trabajo: Ingeniero, Técnico...
Ä Tipo de Contrato: Fijo, Por Horas...
– Deben definirse los atributos y relaciones específicas (si existen).
Una subclase puede tener, a su vez, otras subclases formando así una Jerarquía (hierarchy) o un Retículo (lattice).
• Espec./Generalización JERÁRQUICA: Tiene la restricción de que todas las subclases pertenecen sólo a una superclase.
• Espec./Generalización en RETÍCULO (malla o red): Una subclase puede serlo de varias superclases.
En ese caso, la subclase HEREDA los atributos de TODAS sus superclases (por todos los caminos).
Asociación
Este concepto ya se introdujo.
Ciertas interrelaciones pueden ser estrictamente jerárquicas, en el sentido que una entidad de la relación no existe si no está presente la otra.
Para que esto ocurra, la cardinalidad debe ser (1,1) o (1,n).
Ejemplo.

Agregación
La agregación ayuda a construir entidades de niveles superiores.
Consideremos el siguiente ejemplo:
En este ejemplo se puede referenciar la interrelación Dicta entre los dos tipos de entidad como Curso, la que es una agregación realizada por conveniencia.
En este sentido la agregación permite generar una entidad de nivel superior, la que puede ser utilizada en otra
interrelación.
Ejemplo:

Generalización
Una forma de realizar generalizaciones es utilizar la relación Es_Un, y adaptarla al modelo ER.
Ejemplo. Consideremos la siguiente clasificación.

TIPO UNIÓN o CATEGORIA (union type or category): Subclase que representa una colección de objetos, que son un subconjunto de la UNION de distintos tipos de entidad.
– Ejemplo: Sup. 3 entidades Persona, Banco y Empresa.
• La categoría Propietario de un vehículo incluirá elementos de esos 3 tipos.
• La categoría Propietario es una subclase de la UNIÓN de los 3 tipos.
• También hemos creado la categoría VehículoRegistrado a la que no tienen porqué pertenecer todos los vehículos (puede haber vehículos no registrados). Eso no ocurriría
si se modela siendo {Coche,Camión} una especialización disjunta de Vehículo. Si esa especialización disjunta es PARCIAL indicaría que un Vehículo puede ser de una subclase distinta a {Coche,Camión}. Sin embargo, como Categoría eso no es posible.
– Una CATEGORÍA siempre tiene dos o más superclases (que son distintos tipos de entidad). Una Relación superclase/subclase sólo tiene una única superclase.
– Una CATEGORÍA es similar a una subclase compartida pero:
• Una subclase compartida debe pertenecer a TODAS sus superclases y hereda los atributos de TODAS ellas: Es un subconjunto de la INTERSECCIÓN de las superclases.
• Una CATEGORÍA es un subconjunto de la UNIÓN disjunta de varias superclases: Los miermbros de una Categoría deben pertenecer A UNA de las superclases (no a todas) y heredan sólo los atributos de la superclase a la que pertenezcan.
TIPOS UNION o CATEGORIAS:
• PARTICIPACIÓN en una CATEGORIA:
– TOTAL: Si todas las superclases de la Categoría deben ser miembros de la Categoría.
Una Categoría TOTAL también puede modelarse como Generalización Disjunta, lo cual es preferible si las entidades tienen muchos atributos/relaciones comunes.
Ej.: Un Edificio o Solar siempre debe ser una Propiedad.
– PARCIAL: Si no todas las superclases deben ser miembros de la Categoría.
Ej.: No toda Persona tiene que ser Propietaria (de un Vehículo Registrado).
• Así pues, en una categorización, la subclase o Categoría, debe pertenecer siempre a UNA y SOLO UNA de las superclases, pero las superclases no tienen que pertenecer a la Categoría. Si las superclases
deben pertenecer a la categoría entonces tenemos una Categoría TOTAL y se puede representar también como una Generalización disjunta.
– Recordemos que en toda Generalización todos los miembros de las subclases deben ser también miembros de la superclase. Al revés sólo se cumple si es TOTAL (y no se cumple si es PARCIAL).
jueves, 19 de enero de 2012
Modelo de Datos Jerárquico
El modelo jerárquico fue desarrollado para permitir la representación de aquellas situaciones de la vida real en las que predominan las relaciones de tipo 1 : N.
Es un modelo muy rígido en el que las diferentes entidades de las que está compuesta una determinada situación, se organizan en niveles múltiples de acuerdo a una estricta relación PADRE/HIJO, de manera que un padre puede tener más de un hijo, todos ellos localizados en el mismo nivel, y un hijo únicamente puede tener un padre situado en el nivel inmediatamente superior al suyo.
Esta estricta relación PADRE/HIJO implica que no puedan establecerse relaciones entre segmentos dentro de un mismo nivel.
La representación gráfica de un modelo jerárquico se realiza mediante la estructura de ARBOL INVERTIDO, en la que el nivel superior está ocupado por una única entidad, bajo la cual se distribuyen el resto de las entidades en niveles que se van ramificando. Los diferentes niveles quedan unidos por medio de las relaciones, Las entidades se denominan en el caso particular del modelo jerárquico SEGMENTOS, mientras que los atributos reciben el nombre de CAMPOS. Los segmentos, se organizan en niveles de manera que en un mismo nivel estén todos aquellos segmentos que dependen de un segmento de nivel inmediatamente superior.
Los segmentos, en función de su situación en el árbol y de sus características, pueden denominarse como:
1) SEGMENTO PADRE: Es aquél que tiene descendientes, todos ellos localizados en el mismo nivel.

2) SEGMENTO HIJO: Es aquél que depende de un segmento de nivel superior. Todos los hijos de un mismo padre están en el mismo nivel del árbol.

3) SEGMENTO RAÍZ: El segmento raíz de una base de datos jerárquica es Αel padre que no tiene padre. La raíz siempre es única y ocupa el nivel superior del árbol.

Un ejemplo sería:
Sea una determinada empresa de ámbito nacional con delegaciones por todo el país; esta empresa tiene centralizadas todas las compras de material de sus delegaciones en la oficina central, para lo cual dispone de una base de datos jerárquica que le permite almacenar los datos de todos sus proveedores.
La base de datos de proveedores, denominada PROVEBAS, presenta cinco segmentos. El segmento raíz en el que se almacenan los datos que son comunes a todos los proveedores, como pueden ser: Nombre de la empresa, Director de la empresa, N.I.F., entro otros. Este segmento se denomina DATGEN.
En el segundo nivel del árbol hay tres segmentos dependientes del segmento raíz. El primero de ellos contiene las direcciones de las sucursales de la empresa proveedora, indicando: Calle, Número, ciudad, Tipo de 4dirección, entre otros. El nombre de este segmento es DIRPRO.
El segundo segmento que ocupa este nivel es el que contiene los datos de todos los productos suministrados por cada una de las empresas proveedoras, Este segmento se denota como PRODUC. El último segmento del segundo nivel es el que permite guardar las diferentes notas informativas que sobre un proveedor van remitiendo las delegaciones a la oficina central, este segmento se denomina NOTINF.
El tercer nivel del árbol está ocupado por un solo segmento que es el que permite almacenar las zonas de distribución de cada uno de los productos suministrados por los diferentes proveedores, este segmento se reconoce como AREDIS y depende del segmento PRODUC.

Una OCURRENCIA de un segmento de una base de datos jerárquica es el conjunto de valores particulares que toman todos los campos que lo componen en un momento determinado.
Un REGISTRO de la base de datos es el conjunto formado por una ocurrencia del segmento raíz y todas las ocurrencias del resto de los segmentos de la base de datos que dependen jerárquicamente de dicha ocurrencia raíz.
La relación PADRE/HIJO en la que se apoyan las bases de datos jerárquicas, determina que el camino de acceso a los datos sea ÚNICO; este camino, denominado CAMINO SECUENCIA JERÁRQUICA, comienza siempre en una ocurrencia del segmento raíz y recorre la base de datos de arriba a abajo, de izquierda a derecha y por último de adelante a atrás.
El esquema es una estructura arborescente compuesta de nodos, que representan las entidades, enlazados por arcos, que representan las asociaciones o interrelaciones entre dichas entidades.
La estructura del modelo de datos jerárquico es un caso particular de la del modelo en red, con fuertes restricciones adicionales derivadas de que las asociaciones del modelo jerárquico deben formar un árbol ordenado, es decir, un árbol en el que el orden de los nodos es importante. Una estructura jerárquica, tiene las siguientes características:

El modelo de datos jerárquico presenta importante inconvenientes, que provienen principalmente de su
rigidez, la cual deriva de la falta de capacidad de las organizaciones jerárquicas para representar sin redundancias ciertas estructuras muy difundidas en la realidad, como son las interrelaciones reflexivas y N:M. En la figura 9 se muestran algunos ejemplos de estructuras no admitidas en el modelo jerárquico puro.
La poca flexibilidad de este modelo puede obligar a la introducción de redundancias cuando es preciso instrumentar, mediante el modelo jerárquico, situaciones del mundo real que no responden a una jerarquía; así ocurre con el esquema no jerárquico de la figura 10 cuando se quiere adaptar al modelo jerárquico, donde es preciso crear dos árboles e introducir redundancias, ya que los registros D, H e I aparecen en ambas jerarquías. Se trata de una pobre solución de diseño.
Ya se han señalado los inconvenientes que presenta el modelado del mundo real según esquemas jerárquicos, y también hemos indicado una técnica de diseño jerárquico que consiste en introducir redundancias.


B) Interrelaciones 1:N con cardinalidad mínima 0 en el registro propietario.
El problema es que podrían existir hijos sin padre, por lo que o se crea un padre ficticio para estos casos o se crean dos estructuras arborescentes.
Ya se han señalado los inconvenientes que presenta el modelado del mundo real según esquemas jerárquicos, y también hemos indicado una técnica de diseño jerárquico que consiste en introducir redundancias.

Se podría evitar la pérdida de simetrías introduciendo mucha mayor redundancia, como se muestra en la figura, donde se presenta la transformación de un esquema E/R con dos entidades y una interrelación N:M es un esquema jerárquico en el que existen dos árboles, de modo que se conservan las simetrías naturales, ya que los algoritmos para dos preguntas simétricas, como son recuperar los alumnos de un profesor y recuperar los 10 profesores de un alumno, serían también simétricos.
Soluciones de este tipo no son en absoluto eficientes.
A partir del modelo E/R, vamos a analizar la forma de transformar algunos tipo, de interrelaciones al modelo jerárquico.
A) Interrelaciones 1:N con cardinalidad mínima 1 en la entidad padre.
En este caso no existe ningún problema y el esquema jerárquico resultante será prácticamente el mismo que en el ME/R.

B) Interrelaciones 1:N con cardinalidad mínima 0 en el registro propietario.
El problema es que podrían existir hijos sin padre, por lo que o se crea un padre ficticio para estos casos o se crean dos estructuras arborescentes.

La primera estructura arborescente tendrá como nodo padre el tipo de registro A y como nodo hijo los
identificadores del tipo de registro B. De esta forma no se introducen redundancias, estando los atributos de la entidad B en la segunda arborescencia, en la cual sólo existiría un nodo raíz B sin descendientes.
C) Interrelaciones N:M
La solución es muy parecida, creándose también dos arborescencias.

La solución es independiente de las cardinalidades mínimas. Se podría suprimir, en la primera arborescencia o en la segunda, el registro hijo, pero no se conservaría la simetría.
D) Interrelaciones reflexivas
La jerarquía a) se utilizaría siempre que se desee obtener la explosión.
La aplicación de estas normas de diseño evita la introducción de redundancias, así como la pérdida de
simetría, pero complica enormemente el esquema jerárquico resultante que estará constituido por más de un árbol, lo que no resulta fácilmente comprensible a los usuarios.

Modelo de Base de Datos de Red
El modelo de datos en red general representa las entidades en forma de nodos de un grafo, y las interrelaciones entre estas mediante arcos que unen dichos nodos. En principio esta representación no impone restricción alguna acerca del tipo y el número de arcos que puede haber, con lo que se pueden modelar estructuras de datos tan complejas como sea necesario.
Para definir el modelo de red general con cierta formalización, lo haríamos como un conjunto finito de tipos de entidades:

con sus respectivas propiedades o atributos:

y un conjunto finito de tipos de interrelaciones:

La anterior notación representa la interrelación entre los elementos j, k, ...n, que a su vez pueden ser entidades o interrelaciones, y el superíndice h permite diferenciar dos interrelaciones distintas entre los mismos elementos, ya que se refiere al nombre de la interrelación.

En este modelo, se compone de una componente estática y otra dinámica. La estática estaría compuesta por los objetos (entidades o nodos y atributos), las interrelaciones o arcos y las restricciones, que a su vez pueden ser inherentes (no tenemos en este modelo) y de usuario (pueden ser reconocidas por el modelo de datos o de responsabilidad exclusiva del usuario). Dentro de la componente estática podemos citar un elemento más que atendería a la representación, y son los grafos.
Por otro lado, la componente dinámica estaría compuesta por el aspecto navegacional. El esquema en si representa los aspectos estáticos, es decir, la estructura de los datos, que comprende los tipos de entidades, interrelaciones, etc. Una ocurrencia del esquema son los valores que toman los elementos del esquema en un determinado momento. Estos valores irán variando a lo largo del tiempo debido a la aplicación de los operadores de manipulación de datos a una ocurrencia del esquema.
Por lo visto hasta ahora, el modelo es muy flexible debido a la inexistencia de restricciones inherentes. Esto implica dificultad a la hora de implementarlo físicamente y a la larga poco eficiente. Es por esto que el modelo sea tan solo teórico, y que a la hora de llevarlo a la práctica se introduzcan restricciones.






Siguiendo con el tema, podemos establecer interrelaciones entre más de dos tipos de entidad. El modelo de red general permite las interrelaciones entre cualquier número de entidades como veremos a continuación:

Por tanto el esquema de una base de datos en red general se puede representar mediante diagramas, y la base de datos sería el conjunto de todas las ocurrencias de los tipos de entidad existentes en el esquema con las correspondientes interrelaciones entre ellas.

Como hemos visto, el modelo en red tiene un carácter totalmente general. En el modelo en red no se ha especificado ningún tipo de restricción en lo que respecta a las interrelaciones. Esto quizá haga del modelo en red un modelo tremendamente sencillo de utilizar, pero no deja de tener un carácter general y provoca que en la práctica su instrumentación no resulte nada fácil.
Es por esto, que los SGBD que se basan en el modelo en red, deben añadir una serie de restricciones a fin de poder implementar la base de datos físicamente y obtener un mayor rendimiento del sistema.
miércoles, 18 de enero de 2012
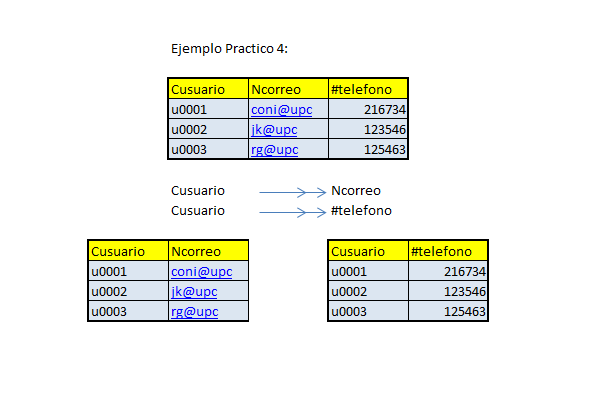
Ejemplo de Normalizacion (1FN a 4FN)
Efectúe la normalización del conjunto de datos propuesto en relación al caso presentado a continuación; explique cada paso y muestre el conjunto de relaciones resultante.
No olvide subrayar la clave primaria en cada relación.
HOSPEDAJES RURALES
La Dirección de Turismo de la Región Lima desea guardar información sobre los alojamientos rurales que existen en su territorio. Para ello decide crear una base de datos que recoja las siguientes consideraciones:
· Un alojamiento rural se identifica con código, tiene un nombre y una dirección.
· En cada alojamiento trabajan una serie de personas que se identifican con un código de empleado, único en todo el sistema. Se requiere conocer además su nombre completo, dirección y DNI. Aunque en un alojamiento trabajen varias personas, cada persona solamente puede trabajar en un alojamiento.
· Los alojamientos se alquilan por habitaciones, y se desea conocer cuántas habitaciones componen cada alojamiento, de qué tipo (individuales, dobles, triples) es cada una, si posee baño propio y su precio.
· Algunos de estos alojamientos organizan actividades multiaventura para sus huéspedes (caminatas, ciclismo de montaña, canotaje, etc.). Estas actividades se identifican con un código único. Es de interés saber el nombre de la actividad, la descripción y el nivel de dificultad, el cual es propio de la actividad (es decir, la dificultad no depende del alojamiento que la organice).
· Estas actividades se realizan uno o más días a la semana en cada alojamiento. Por ejemplo, en el alojamiento L005 hay canotaje los miércoles, sábado y domingo; en el alojamiento L042 hay canotaje martes, sábado y domingo, y ciclismo de montaña los lunes, miércoles y viernes.
· Los alojamientos registran a sus huéspedes asignándoles un código de identificación (único en cada alojamiento), y registrando su nombre completo y su nacionalidad. Se debe conocer además todas las ocasiones en que se hospedó cada huésped, guardando la información la habitación que ocupó y del período de hospedaje en términos de la fecha de llegada y de salida del alojamiento. Esto es muy importante puesto que hay personas que regresan muchas veces al mismo alojamiento, en sus vacaciones o aprovechando fines de semana largos.

No olvide subrayar la clave primaria en cada relación.
HOSPEDAJES RURALES
La Dirección de Turismo de la Región Lima desea guardar información sobre los alojamientos rurales que existen en su territorio. Para ello decide crear una base de datos que recoja las siguientes consideraciones:
· Un alojamiento rural se identifica con código, tiene un nombre y una dirección.
· En cada alojamiento trabajan una serie de personas que se identifican con un código de empleado, único en todo el sistema. Se requiere conocer además su nombre completo, dirección y DNI. Aunque en un alojamiento trabajen varias personas, cada persona solamente puede trabajar en un alojamiento.
· Los alojamientos se alquilan por habitaciones, y se desea conocer cuántas habitaciones componen cada alojamiento, de qué tipo (individuales, dobles, triples) es cada una, si posee baño propio y su precio.
· Algunos de estos alojamientos organizan actividades multiaventura para sus huéspedes (caminatas, ciclismo de montaña, canotaje, etc.). Estas actividades se identifican con un código único. Es de interés saber el nombre de la actividad, la descripción y el nivel de dificultad, el cual es propio de la actividad (es decir, la dificultad no depende del alojamiento que la organice).
· Estas actividades se realizan uno o más días a la semana en cada alojamiento. Por ejemplo, en el alojamiento L005 hay canotaje los miércoles, sábado y domingo; en el alojamiento L042 hay canotaje martes, sábado y domingo, y ciclismo de montaña los lunes, miércoles y viernes.
· Los alojamientos registran a sus huéspedes asignándoles un código de identificación (único en cada alojamiento), y registrando su nombre completo y su nacionalidad. Se debe conocer además todas las ocasiones en que se hospedó cada huésped, guardando la información la habitación que ocupó y del período de hospedaje en términos de la fecha de llegada y de salida del alojamiento. Esto es muy importante puesto que hay personas que regresan muchas veces al mismo alojamiento, en sus vacaciones o aprovechando fines de semana largos.
| Elemento de dato | Definición |
| #_Telefono | Número de Teléfono del alojamiento |
| $_Habitacion | Costo de alquiler de la habitación |
| C_Actividad | Código de identificación de la actividad |
| C_Alojamiento | Código de identificación del alojamiento |
| C_DNIEmpleado | DNI del empleado |
| C_Empleado | Código de identificación del empleado |
| C_Habitacion | Código de identificación de la habitación dentro del alojamiento al que pertenece |
| C_Huesped | Código de identificación del huésped dentro del alojamiento |
| D_FinHospedaje | Fecha en que el huésped se retira del alojamiento |
| D_IniHospedaje | Fecha en que el huésped llega al alojamiento |
| F_Baño | Indicador de si la habitación cuenta con baño incorporado |
| N_Actividad | Nombre de la actividad (ciclismo de montaña, canotaje, etc.) |
| N_Alojamiento | Nombre del alojamiento |
| N_DiaSemana | Día de la semana en que se realiza una actividad en un alojamiento |
| N_Dificultad | Grado de dificultad de la actividad |
| N_Empleado | Nombre y apellidos del empleado |
| N_Huesped | Nombre y apellidos del huésped |
| N_Nacionalidad | Nacionalidad del huésped |
| N_TipoHabitacion | Nombre del tipo de habitación (simple, doble, triple) |
| T_Actividad | Descripción de la actividad |
| T_DirecAlojamiento | Dirección del alojamiento |
| T_DirecEmpleado | Dirección del empleado |
Paso #1 - Armar el diagrama de dependencias y definir la PK:

Determinantes: (C_Actividad, C_Alojamiento, C_Empleado, C_Habitacion, C_Huesped, D_IniHospedaje)
Atributo en DMV no soportado por el conjunto de determinantes: N_DiaSemana
(C_Empleado) determina C_Alojamiento
(C_Alojamiento, C_Huesped, D_IniHospedaje) determinan C_Habitacion
è PK: (C_Actividad, C_Empleado, C_Huesped, D_IniHospedaje, N_DiaSemana)
R: (C_Alojamiento, C_Actividad, C_Empleado, C_Habitacion, C_Huesped, #_Telefono, $_Habitacion, C_DNIEmpleado, D_FinHospedaje, D_IniHospedaje, F_Baño, N_Actividad, N_Alojamiento, N_DiaSemana, N_Dificultad, N_Empleado, N_Huesped, N_Nacionalidad, N_TipoHabitacion, T_Actividad, T_DirecAlojamiento, T_DirecEmpleado)
Paso #2 - Trabajamos las DMV:
Actividad en Alojamiento: (C_Alojamiento, C_Actividad, N_DiaSemana)
Paso #3 - Armar relaciones donde haya DFC:
Actividad: (C_Actividad, N_Actividad, N_Dificultad, T_Actividad)
Empleado: (C_Empleado, C_Alojamiento, C_DNIEmpleado, N_Empleado, T_DirecEmpleado, N_Alojamiento, #_Telefono, T_DirecAlojamiento)
Huésped: (C_Alojamiento, C_Huesped, N_Huesped, N_Nacionalidad)
Hospedaje: (C_Alojamiento, C_Huesped, D_IniHospedaje, D_FinHospedaje, C_Habitacion)
Habitación: (C_Alojamiento, C_Habitacion, $_Habitacion, N_TipoHabitacion, F_Baño)
Paso #4 – Despejar las DT que hubiera:
Empleado (1): (C_Empleado, C_Alojamiento, C_DNIEmpleado, N_Empleado, T_DirecEmpleado)
Alojamiento: (C_Alojamiento, N_Alojamiento, #_Telefono, T_DirecAlojamiento)
Conjunto Solución: {Actividad en Alojamiento, Actividad, Empleado (1), Alojamiento, Huésped, Hospedaje, Habitación}
Cuarta Forma Normal (4FN)
Una relación está en cuarta forma normal (4FN) si es BCFN y no contiene dependencias multivalor.
Se comenzara explicando la forma normal de boyce/codd que consiste en volver a toda determinante en clave candidata, con lo que se evitan problemas de redundancia de datos.
Ahora, el concepto de dependencias multivalor (DM), que hace referencia ya no a una dependencia funcional que podía ser de muchos a uno o de uno a uno, sino a una de muchos a muchos. Dicho de otra manera para un atributo “X” de una relación R, le corresponden varios valores de otro atributo “Y” y viceversa, cumplida dicha condición se habla de una dependencia multivalor entre “X” e “Y”.







Suscribirse a:
Comentarios (Atom)